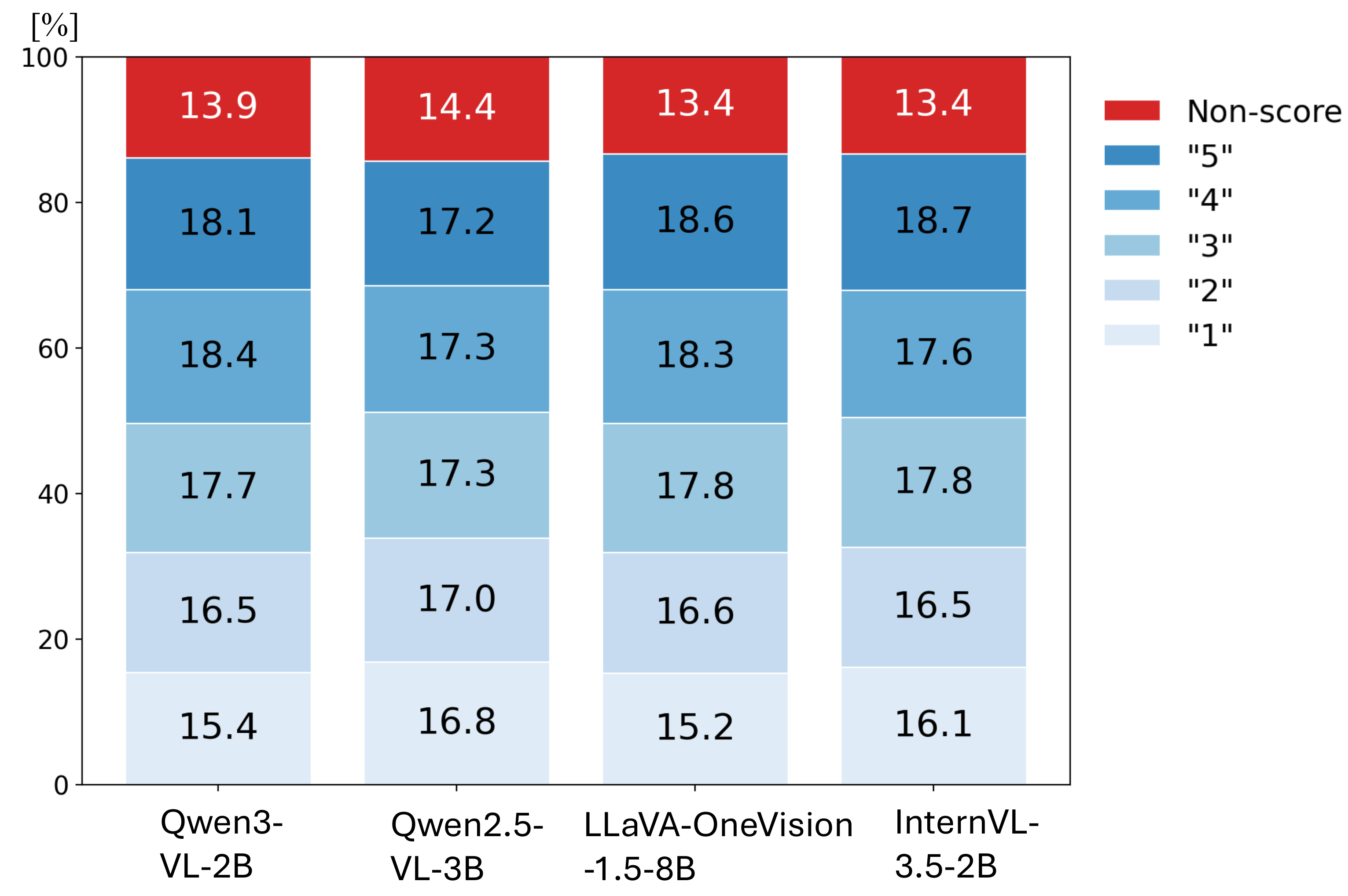
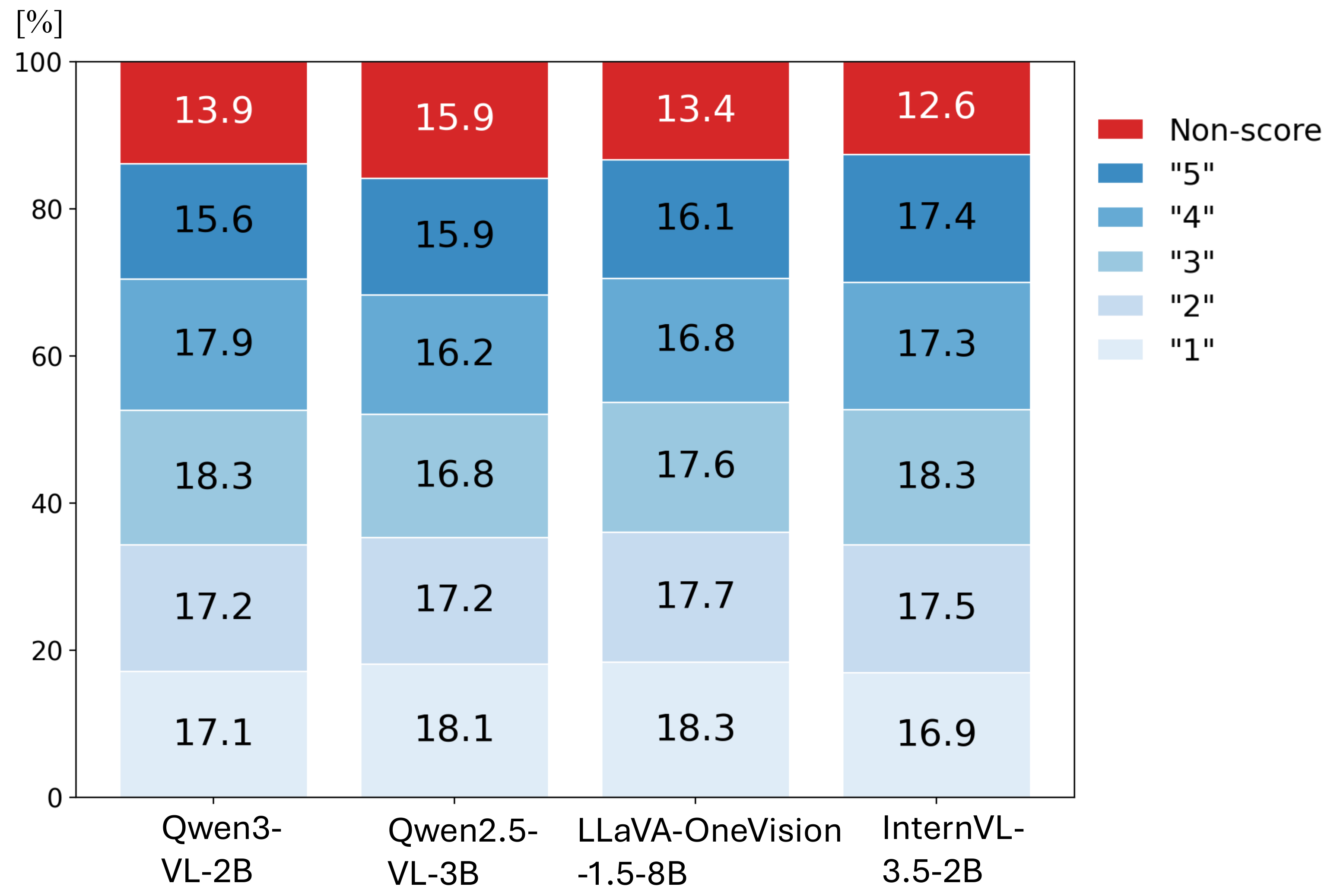
Abstract
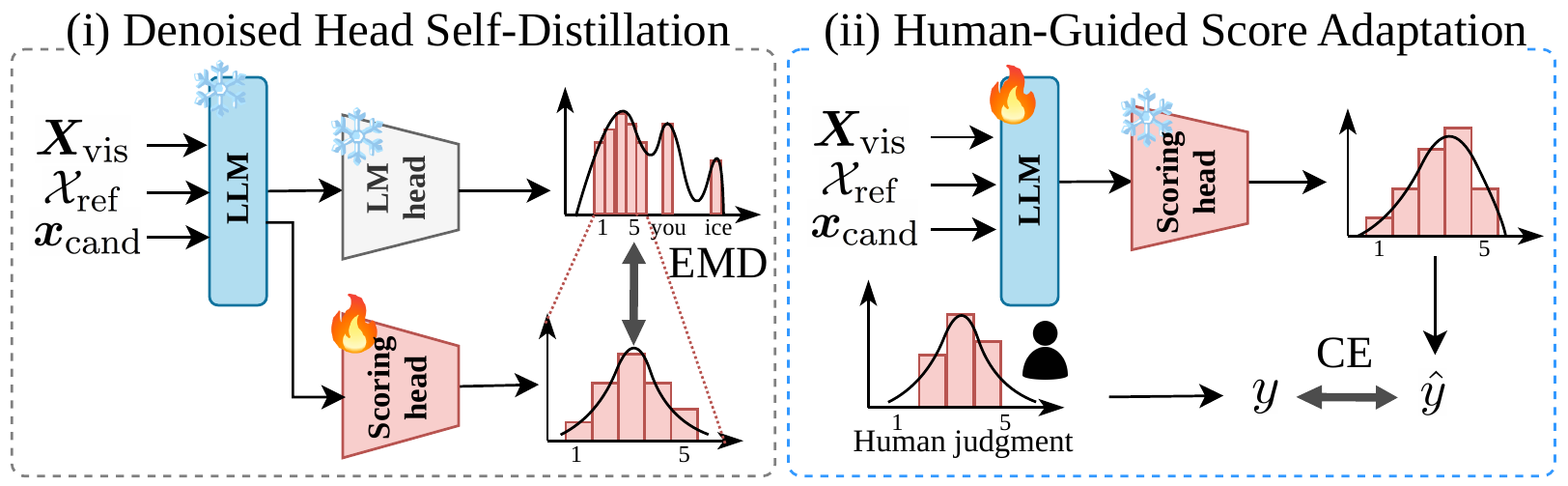
Automatic evaluation of image and video captioning is essential for benchmarking multimodal systems; however, standard evaluation metrics show limited alignment with human judgments. Recent LLM-as-a-Judge approaches have improved alignment with human judgments but still suffer from a mismatch between large-vocabulary language modeling and evaluation over a small label set. To address this, we propose Rigel, an automatic evaluation metric for image and video captioning, based on self-distilled score adaptation. The metric employs an evaluation-specific scoring head distilled from a frozen LLM, which captures judgment signals in a task-aligned space without relying on large-vocabulary token sets. We then refine the LLM backbone with human judgment data. To train Rigel, we construct the Vid-Lepus dataset containing 3,338 video clips, 33,380 reference captions, and 5,637 candidate captions. Experiments on multiple benchmarks show that Rigel outperforms state-of-the-art metrics, achieving over 10-point improvements on ActivityNet-Fact.
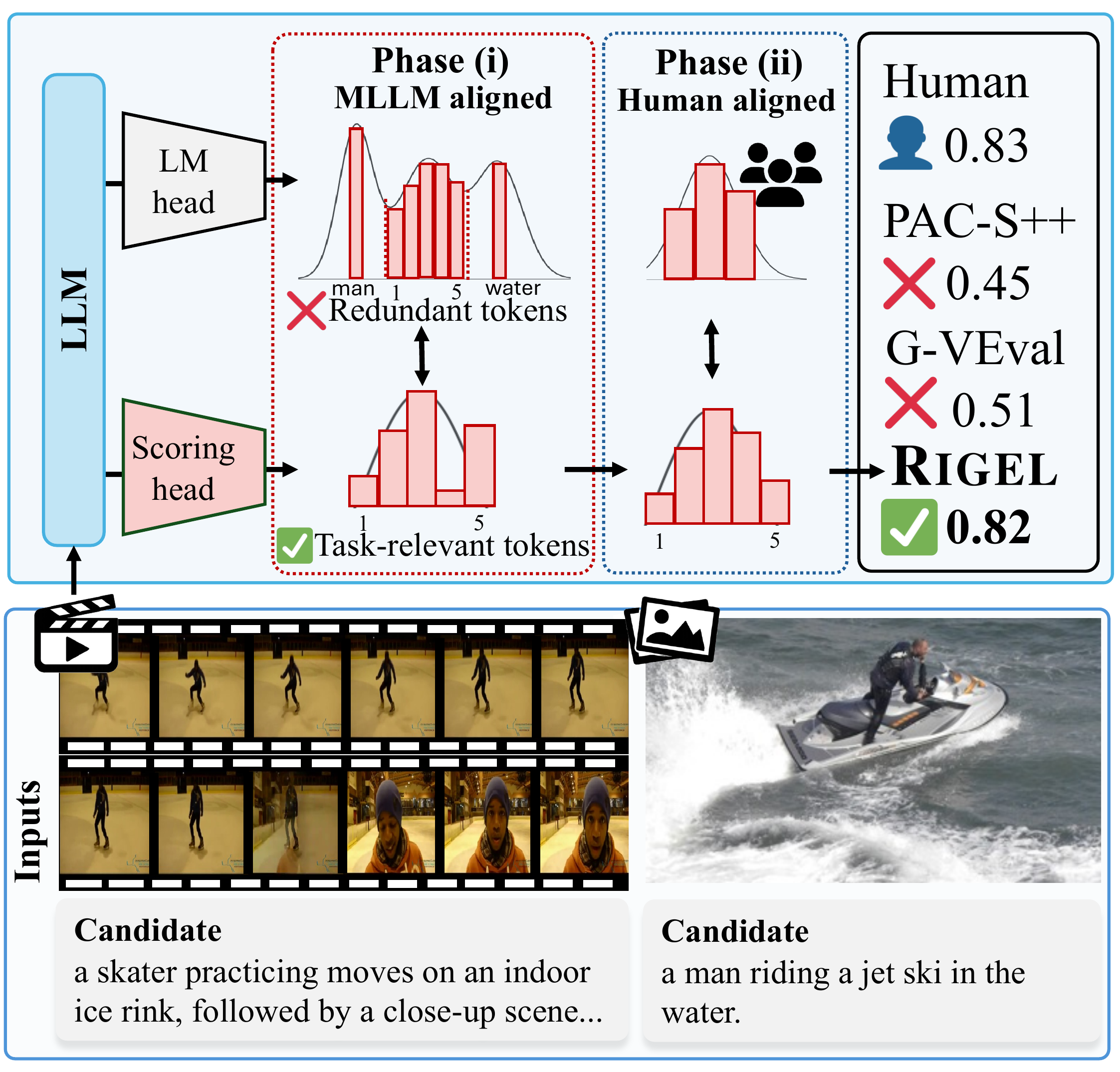
Rigel is an automatic evaluation metric for image and video captions, based on self-distilled score adaptation.